The Robert J. and Nancy D. Carney Institute for Brain Science is home to one of the foremost explainability research groups in the world, led by Thomas Serre, the associate director of Carney’s Center for Computational Brain Science. The group focuses on models trained to perform vision tasks and develops both custom-made techniques and user-friendly resources that bust open AI black boxes. This work allows researchers to catch issues in AI-enabled tech before they fail–and before a human needs them most.

Serre and his team debunked published claims that a deep neural network model can do a more precise job of diagnosing cancer than a human pathologist. The finding illustrates the need for explainability, particularly when the technology in question is intended to help humans make life-or-death calculations. Highlighting the techniques the team used offers a sneak peek into how they do some of their most difficult and important work.
“We need to stop treating these models as black boxes,” Serre said, “and really start to be more skeptical when they succeed in solving tasks that are assumed to be very hard or impossible.”
Why Explainability?
Drew Linsley, an assistant professor of cognitive and psychological sciences at Brown and a member of Serre’s group, said there’s a simple reason that XAI is needed: deep neural network models are trained by humans, and humans are fallible.
“If you’re not careful about what you’re doing when you train a model at a task, you leave an opportunity for it to take a shortcut,” said Linsley.
LENS, one of the publicly-accessible explainability resources built by the group, illustrates Linsley’s point, uncovering for researchers and laypeople alike which visual features a model leverages to decide what object it is looking at.

For example, putting “bee” into the LENS search bar shows that, because the dataset the LENS model was trained on contained many instances of bees near or on flowers, the model latched onto flower petals to identify bees, just as it did bee wings or abdomens. This means the model could be making a correct identification for an incorrect reason, and would probably have trouble recognizing a bee in contexts where it was not near or on a flower.
The group found that a model trained to diagnose cancer was taking a similar shortcut. They had read articles in Nature and again in Nature Medicine that claimed a model could identify different types of cancer mutations in human tissue. This is a task a histopathologist–an expert physician who examines tissue under a microscope to identify the presence of infections, inflammatory diseases, and cancer–cannot do by eye.
The group knew it was possible for AI to perform superhuman visual feats that lead to biomedical breakthroughs. In 2021, they showed with explainability methods that a model could detect cell death with superhuman accuracy and speed, making it an enormously helpful tool for understanding how neurodegenerative diseases work. If it turned out a model could discern as-yet-unseen details of cancer mutations in human tissue samples, it would mean a similar victory for oncology.
But, since the earlier cancer diagnostics studies hadn’t used explainability methods to support their claims, it was also possible that the exciting results were due to a bias or shortcut in the model’s predictions.
In developing a custom explainability framework to refute or validate the studies’ results, the group was faced with a complex problem typical of this new field: how to devise a test only a superhuman can pass, but that a human can validate?
A Test Fit for a Superhuman
When a patient is diagnosed with certain types of cancer, like lung or breast, the next very important step is for healthcare providers to identify a genetic mutation driving the cancer, because treatments differ from mutation to mutation. While histopathologists can locate cancerous tissue visually, determining mutation type is something they can only get at by sending tumor samples away to be analyzed molecularly–a costly and time-consuming process. Automating this procedure with deep neural networks would represent an enormous opportunity for improving healthcare.
Serre’s group decided to test their model’s ability to distinguish between mutation types using lung cancer tissue samples provided by the Moffitt Cancer Center. To act as point person on this work, Serre tapped his former student Sahar Shahamatdar. Currently a medical resident at Massachusetts General Hospital, Shahamatdar was a Brown MD/PhD student at the time of this project and is a first author on the paper the group published.
To create visual samples of mutation types, the group turned to a technique called laser capture microdissection, which uses a laser to precisely cut out specific cells under a microscope. The laser’s job was to isolate clusters of cells that change due to a mutation in KRAS, which is responsible for about 20% of all lung cancers.
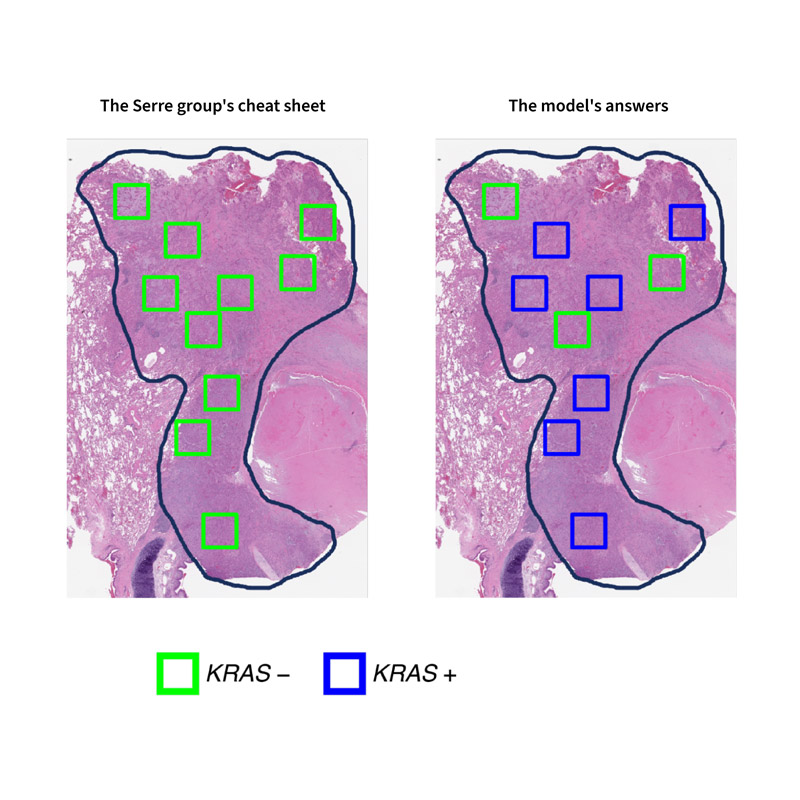
Next, Serre’s team created a test for their model and a cheat sheet for themselves. They got their cheat sheet by molecularly profiling each cluster of cells. They trained their model by showing it clusters that she knew contained either KRAS negative or KRAS positive mutations. Then, they showed the model a slide containing many different clusters and asked it to identify each one. If there was a tiny visual difference between the two mutation types, the model was trained to find it.
The test results told the group both what the model was really doing under the hood–and why earlier studies had missed this.
The model was not using its superhuman vision to identify certain mutations. It was guessing–often incorrectly.
So, what went wrong?
The researchers who produced the original cancer results had trained their models by showing them ordinary slides of cancerous tissue, which, unlike the high-resolution test the Serre group created with a laser, contained many visual features unrelated to genetic mutations. The models used these other visual features to make a prediction.
For example, the Serre group was able to determine that, when they showed their model an ordinary slide, it latched onto visual features related to inflammation to make its prediction. While this enabled the model to correctly guess mutation type most of the time, inflammation is only weakly associated with genetic mutations and can occur in tissue for many reasons that have nothing to do with cancer at all.
Basically, the model was doing the equivalent of predicting a bee from flower petals.
The Importance of Working Across Fields
When developing an explainability test like this one, Serre and Linsley were quick to point out, it’s not just a matter of having the computer science chops.
“You need to be working with experts in the field in which you’re seeking to innovate, or the risk of bias increases,” said Serre.
For this project, Serre said his relationship with Moffitt researchers, Brown faculty member and data scientist Sohini Ramachandran, and Shahamatdar were all critical. Shahamatdar’s role as a translator conversant in both medicine and computer science was especially important, since she needed to learn how Moffitt histopathologist Daryoush Saeed-Vafa did his job, train the group’s model in those same skills, and relay the results of the test to all constituents for a consensus.
As AI and biomedical research continue to come together, this Carney group and their trainees will be a vital bridge between computer scientists and clinicians.
“We’re training undergraduate and graduate students not just in artificial intelligence but in one hundred-plus years of brain and cognitive science,” said Linsley. “Our trainees are poised to be at the forefront of AI/biomedical advances, making sure that they are reliable as well as revolutionary.”